Jump to
Web applications are arguably your organization’s most visible assets—critical to the business and more accessible than many others within your estate.
The Verizon Data Breach Investigations Report for 2022 indicates that approximately 45% of all breaches involved web applications in some capacity. Generally, organizations’ actions to defend against this are:
- fix identified vulnerabilities reactively
- try to prevent issues proactively, using through-life validation activities like penetration testing and embracing DevSecOps practices and threat modelling
- identify breaches with infrastructure-focused detection and response strategies, usually during later stages of the kill chain, such as lateral movement or privilege escalation activities.
The solution is rarely to introduce detection and response at the application level, due to a perceived lack of value or unjustifiable technical complexity. This misses the opportunity to identify early signs of an attack and leaves organizations with decreased visibility of their critical apps, compared to other critical assets like their Windows domain.
Attackers invariably attempt to find ways around security controls through compromised credentials, or even through abuse of legitimate functionality and workflows. Examples of this include the vulnerabilities disclosed in the SaltStack framework or the Magecart attacks against third-party dependencies in applications, where in both cases, the issues lay with the third-party and not with the security of the organization. If applications can maintain the ability to log activity on users’ interactions with them, alert organizations to attack indicators within those logs, and respond proactively to prevent a breach, organizations would have a better awareness of the attacks they face. Whether they are anticipated or unforeseen, this would give the organization a better chance of preventing them earlier.
In recognition of this issue, the concept of attack aware applications (applications that effectively log, alert, and respond to threats) was introduced over a decade ago. Multiple approaches to this include:
- Creating that awareness natively at the code level using frameworks like OWASP’s AppSensor, which is powerful but can be very taxing.
- Using generic tools such as Web Application Firewalls (WAFs), which are low effort and extensively cover common vulnerabilities but lack context and cooperation with in-house systems. These also focus primarily on known malicious traffic such as vulnerability exploitation, missing the opportunity to identify abuses of legitimate behavior.
- Leveraging traditionally anti-fraud techniques, such as services to fingerprint users and staff, manually monitoring web application traffic and sessions, and responding to malicious activity by terminating sessions. This is a primarily people-based approach often used for critical apps, though it can be costly and difficult to scale.
These approaches fail to bridge the full detection and response gap for applications, each presenting only part of the solution. Any successful universal solution would therefore have to be low effort, clear in its coverage (and eventually comprehensive), and scalable. Our consultants have been exploring the concept of application-level purple teaming as a solution for organizations to gradually begin implementing attack awareness.
Our motivation for this research was in direct response to an engagement where we were able to achieve end-to-end compromise of a client’s estate, using a web application as the entry point. The organization in question generally had a strong security posture following considerable investment to enhance its resilience through a developed security program; yet blind spots were identified. We came to discover that app-level detection and response was also an issue for similar organizations working with us.
In this article, we discuss our methods, which focus on iterative, collaborative improvement. This seeks to take a modular approach: using specialized components that are ubiquitous within the detection and response space and by minimizing costly code level effort. This should help organizations gain visibility of attacks earlier in the kill chain and allow for high fidelity alerting of attacks across critical applications. We explore this in depth in a technical case study on our Labs website.
An introduction to attack-aware applications
Attack-aware applications generate sufficient and relevant data to enable the detection of malicious activity and deviations from usual behavior, allowing for appropriate responsive action to be taken.
Projects like OWASP’s AppSensor have attempted to provide a framework for making apps attack aware by defining set “detection points” and example responses. AppSensor defined over 50 detection points, stressed the importance of context, and even came built with a reference application.
Similarly, John Strand’s book Offensive Countermeasures: The Art of Active Defense categorized organizations’ work in this space into annoyance, attribution and attack. This included many well-understood but underutilized techniques, such as honeypots and, in the case of applications, honeytokens (such as files not intended to be accessed to serve as a high-fidelity attack indicator, random link generators to delay web scanners, means of fingerprinting attackers, and callbacks in documents and embedded within client-side application code). The techniques discussed range beyond applications to client domains as well. Though first published in 2013, its techniques are still underutilized by enterprise organizations’ applications.
The broad focus of attack-aware applications should surely be to improve detection and response at the application level. However, there has been a disconnect between the primarily software- and development-focused security concerns of attack-aware application approaches and the general principles of traditional detection and response teams up until this point.
In that same time period, focus on detection and response within cyber security has increased, encouraged by the advent of purple teaming—the activity of measuring and improving an organization’s ability to detect indicators of malicious activity by combining offensive red team techniques with defensive blue team indicators and methods. This has led us to understand that an effective detection process broadly consists of three key steps:
- Log the presence of malicious indicators in a central, aggregated location to prioritize ease of querying and accuracy of data. This is also referred to as telemetry. Log data will vary in its provenance and in the attack types it can cover.
- Alert the appropriate staff to malicious indicators in that log data. Built on top of good log data, alerts can signal known bad indicators or multiple, individually benign log entries, which only together are suspicious; they do not need to rely on a single event. This often utilizes tools such as SIEMs (Security Information and Event Management) and visualization dashboards.
- Respond to those alerts—whether manually or automatically. Response (the concept that a target can fight back or protect itself from an attacker) is particularly interesting in the case of web applications. Often an organization’s most exposed assets, these could limit their own attack surface by taking steps to lock accounts, rate limit source IP addresses, or serve up fake data to deter further attacks.
In its 2015 AppSensor CISO Briefing paper, OWASP included the following quote:
“Make application self-protection a new investment priority, ahead of perimeter and infrastructure protection…We believe that by 2020, 25% of Web and cloud applications will become self-protecting, up from less than 1% today.” Joseph Feiman, Gartner, Sep. 2014
The focus on self-protection within AppSensor-style approaches (i.e., the response part of attack-aware applications) often overshadows the fundamental requirements for logging and alerting. Response is arguably the most appealing element of attack-aware apps, but its premature focus detracts from progress in logging and alerting. Now in 2020, our consultants’ observations lead us to estimate the current state of app-level detection and response adoption at still less than 1%.
Why is adoption of app-level detection and response so low?
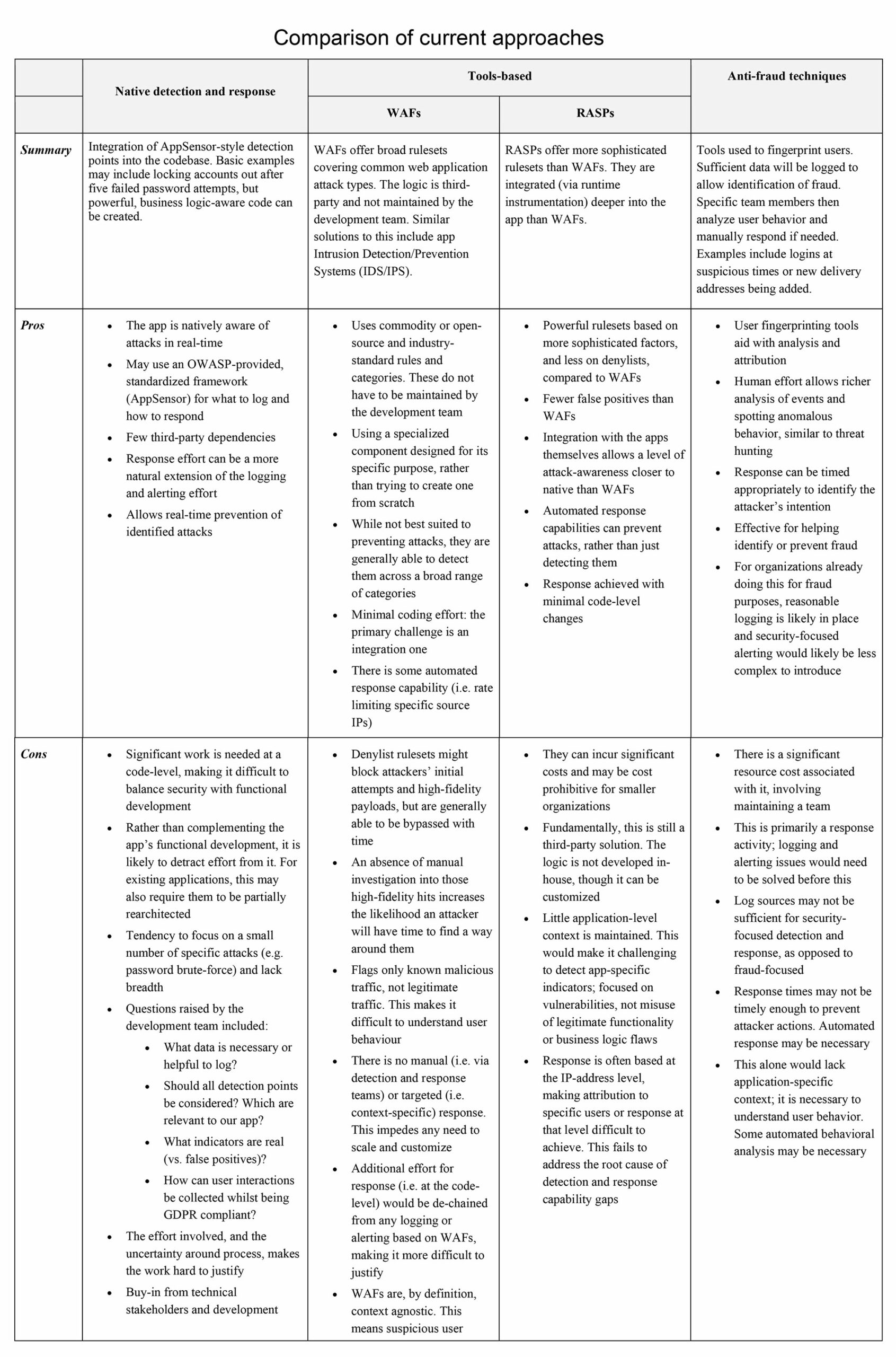
We have observed three key approaches to detection and response at an app level. The first adopts them natively (like AppSensor); to assess this approach, we worked with a development team to identify the reasons why integrating detection points and response at the app level for a customer-facing web application might lack appeal for organizations. The second uses non-native tools such as web application firewalls (WAFs) and runtime application self-protection tools (RASPs) to perform various roles needed to make an app attack aware. The third, more common in larger organizations, involves use of existing anti-fraud techniques, including manual intervention.
An overview of these extant solutions and the limitations that challenge them is broken down in the pop-out table, below.
Questions raised by the development team regarding native, code-level solutions included:
- What data is necessary or helpful?
- Should all detection points be considered?
- What indicators are real (vs false positives)?
- How can user interactions be collected whilst being GDPR compliant?
Therefore, we identified that a solely native, tools-based or anti-fraud/manual approach did not address the fundamental gap of introducing detection and response at the application level; they either solved only part of the problem or required unrealistic effort. Our activities led us to believe any successful efforts in this area would have to align to six key principles. This is described in brief below.
For our case study of an application-level purple teaming approach to this problem, the activities looked decidedly different to traditional purple teaming. The offensive techniques we used were tailored to the specific in-scope application and its key threats, with payloads being relatively simple; there was no blue team involvement yet, with the collaboration instead coming with the development team. First, we had to establish strong fundamentals. More traditional purple teaming with advanced and numerous payloads and techniques, and collaboration with the blue team, would not be beneficial until later in the process.
The principles of app-level purple teaming
1. Iteration
Constantly improve by assessing the app’s ability to log activity, alert malicious behavior, and eventually respond; a fully attack-aware app shouldn’t be expected straight away. Trace payloads through all of log → alert → respond, looking at the logs at various levels and in SIEM tools and visualization dashboards (e.g., Splunk, Kibana, etc.). Response may take multiple, evolving forms, such as manual, targeted, or automated. Automated app response (giving an app the ability to fight back against attackers and restrict them in near real time) is the most powerful form of active defense when compared to manual response, but we should not focus on this prematurely. Strong detective fundamentals must be in place first.
2. Categorization of test cases
Test across different contexts—attack types and indicators of compromise through the kill chain—according to their impact. Industry-standard comparisons such as MITRE ATT&CK can be useful.
App-level purple teaming can be loosely aligned to MITRE’s ATT&CK framework to help stakeholders understand its purpose within a broader detection and response strategy. It is suited to identifying attacks earlier in the kill chain, where currently the emphasis is largely weighted in post-compromise phases like lateral movement and privilege escalation. Due to the relative immaturity of app-level purple teaming, full alignment may not be feasible; the tactics and techniques within ATT&CK are largely not relevant to apps. However, showing a basic capability against at least kill-chain phases can help demonstrate the value introduced by the app-level focus to stakeholders. This is visualized below in WithSecure’s adapted version of Lockheed Martin’s cyber kill-chain and uses the categories and test cases from our app-level purple team case study.
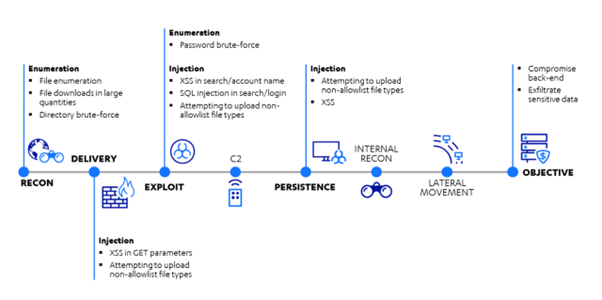
Fig. 1. Adapted kill chain for app-level purple teaming
Compared to the MITRE ATT&CK phases, the example activities demonstrated here primarily reside in discovery, initial access, execution, and persistence.
3. Reuse of existing tools and systems
Rather than building functionality from scratch, use tools that are optimized for their specific role to reduce workload and simplify integration between tools; this modularizes the problem. In our case study, this included using the ELK stack (Elasticsearch, Logstash, Kibana). Open source WAFs like ModSecurity may also be leveraged, or deployment-specific ones such as the AWS WAF if operating within the cloud.
It is important to consider the general workflows that your organization’s detection and response team currently use and how the log data and alerts generated by your apps can feed into them. Where possible, alignment is desirable to save future work on both sides.
4. Minimizing code changes
Though many approaches to application-level detection and response focus on building awareness natively, our research has shown that offline analysis provides the most economical reward.
Concerns that response would require extensive coding and could not cooperate with the use of existing tools and systems were quashed during our case study; for example, we found we could reuse processes for sending alert data from Elasticsearch to Kibana to also send to a given endpoint or webhook on the app. From there, the app was expected to reuse as much functionality as possible, like reusing an existing call to lock an account, or to require one-time password (OTP) authentication.
In future, integrating techniques such as honeytokens could be accomplished using short-term sprints, once the fundamentals had been introduced.
5. Multi-app integration
Integrate multiple, logically distinct applications in the process. Each application simply becomes a separate log source within a common pipeline, enabling clearer visibility across your suite of critical applications.
This may allow the following cases to be identified:
- Attackers targeting specific apps: for example, if one app has an increased attack surface, is on the radar of attackers, or is viewed as a weak link.
- Attackers targeting multiple apps: indicating attacks such as password spraying, or that an attacker has targeted other apps and deemed them too secure, moving on to others.
6. Collaboration
Work closely with your development team—they are essential to the success of the activity. More broadly across the business, purple teaming is perfectly suited as a vehicle for learning and upskilling.
As the process progresses, this focus should move to collaboration between red and blue teams, with the detection and response team ready to be brought into the discussion once the fundamentals are in place.
Conclusion
In our case study, the architecture for an approach guided by those six principles looked like the following.
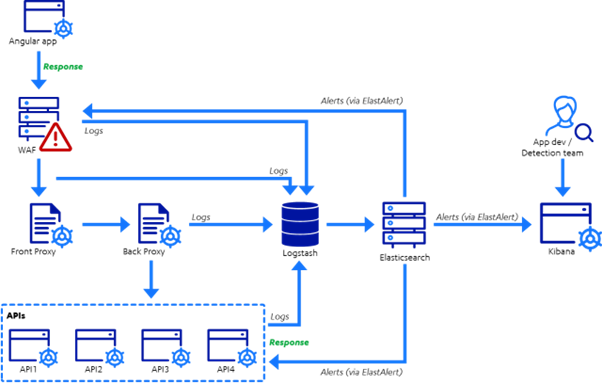
Fig. 2. An exemplar architecture for application-level logging, alerting, and response, built iteratively using our application-level purple team approach.
Organizations deploying detection and response for other assets will hopefully find it logical to expand these efforts to critical applications and new environments. Detection and response yield the best results when carried out collaboratively, continuously, and iteratively, such that progress is always being made, rather than aiming immediately for the perfect attack-aware app. Gradual improvements to app-level detection can have a significant positive impact upon an organization’s security monitoring capability, enabling indicators of malicious activity to be detected and responded to in previously unidentifiable areas of the attack lifecycle.
For an in-depth, technical exploration of this approach, please refer to the case study on Labs, where we cover:
- the threat modelling and identification of appropriate metrics, categories, and test cases
- our specific categories and test cases, and their broad alignment to the kill-chain approach
- identifying relevant log sources with the development team
- introducing sufficient logging across our categories to then allow specific, high-fidelity alerting on attacks such as access control violations
- examples of those alerts in Kibana
- description of the technology stack we used for alerting, including example ElastAlert rules
- discussion of how this could be used to enable response.




{kind=link}